数据网格架构模式 构建可扩展的数据处理与存储支持服务体系
随着企业数据规模与复杂性的急剧增长,传统集中式数据湖或数据仓库架构在敏捷性、可扩展性和领域自治方面面临严峻挑战。数据网格(Data Mesh)作为一种新兴的分布式、领域驱动的数据架构范式,应运而生。其核心理念是将数据的所有权、治理和交付责任下放至最接近数据源和业务需求的领域团队,同时通过标准化的平台支持服务,确保全局的可发现性、互操作性与安全性。本文将重点探讨数据网格架构中,支撑其成功落地的关键支柱——数据处理与存储支持服务。
数据处理与存储支持服务的核心角色
在数据网格架构中,数据处理与存储不再由一个中心化的数据平台团队垄断式管理,而是演变为一套可供各领域数据产品团队自助使用的、平台化的支持服务。这些服务旨在降低领域团队管理数据基础设施的复杂性,使其能够专注于构建高价值的领域数据产品。其核心角色包括:
- 提供抽象与标准化接口:将底层复杂的数据处理引擎(如Spark、Flink)和存储系统(如对象存储、数据库)封装成统一、易用的API、SDK或声明式配置界面,使领域团队无需深究技术细节即可完成数据的摄取、转换、存储与发布。
- 实现自助式服务:领域团队能够按需、自助地申请和配置计算资源、存储空间以及数据处理流水线,实现快速迭代和独立部署,大幅缩短数据产品从开发到上线的周期。
- 保障全局性能力:作为数据网格的“骨干网”,这些支持服务必须强制实施跨领域的数据治理策略、安全标准(如加密、访问控制)、元数据管理和可观测性(监控、日志),确保分布式数据生态的整体健康与合规。
关键服务组件详解
一个完善的数据处理与存储支持服务平台通常包含以下核心组件:
1. 数据产品运行时与存储服务
- 托管存储服务:提供多种存储选项的托管,例如面向原始数据的低成本对象存储(如S3兼容存储)、面向高性能查询的分析型数据库(如ClickHouse、Snowflake服务)、以及面向数据产品的API化数据服务层。服务需支持数据产品定义其数据的SLA(服务等级协议),如可用性、新鲜度。
- 数据处理流水线编排:提供工作流编排引擎(如Airflow、Kubernetes Jobs、专用的数据流水线服务),支持领域团队定义、调度和监控其数据转换与加工任务。平台应提供可复用的处理器模板和函数(如数据质量检查、标准化清洗)。
2. 数据基础设施即代码(IaC)与开发工具
- 基础设施供应:通过Terraform、Crossplane或平台专用DSL,允许领域团队以代码形式声明其所需的数据管道、存储桶、数据库表等资源,实现版本控制、可重复部署和环境一致性。
- 开发者体验(DevEx)工具:提供CLI工具、IDE插件、本地测试沙箱等,让数据开发者能在本地轻松构建、测试和调试数据产品,享受与应用程序开发一致的流畅体验。
3. 元数据与可发现性服务
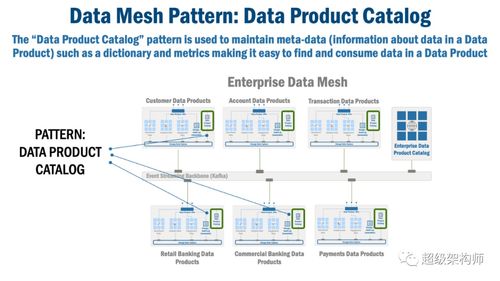
- 数据目录与血缘:自动从各数据产品中采集技术、业务和操作元数据,构建全局数据目录。清晰展示数据的来源、转换过程(血缘)、质量指标、所有者信息和使用情况,是数据可发现和可信赖的基石。
- 语义层与搜索:提供统一的业务术语表(Glossary)和语义模型,支持通过业务关键词搜索和发现所需的数据产品,降低数据消费门槛。
4. 治理、安全与可观测性服务
- 策略即代码:将数据治理策略(如隐私合规、数据保留周期)和安全策略(如基于属性的访问控制-ABAC)编码化,并集成到数据产品创建和发布的各个环节中自动执行。
- 统一监控与SLO管理:集中收集所有数据产品及其管道的运行指标、日志和跟踪信息,提供仪表盘和告警,使领域团队和平台团队都能清晰了解数据产品的健康状况,确保其满足定义的SLO。
实施挑战与最佳实践
构建此类支持服务并非易事,组织常面临文化转变(从集中控制到领域自治)、技术平台选型与整合、初期投资成本等挑战。以下最佳实践可供参考:
- 循序渐进,从赋能开始:避免“大爆炸”式改革。首先识别一两个高意愿、高能力的领域团队作为试点,与他们共同打造最小可行平台(MVP),在实践中迭代平台能力,树立成功样板。
- 平衡自治与标准化:平台团队应提供“铺好铁轨”的强标准(如接口协议、元数据模型、安全基线),但在“跑什么车”(具体业务逻辑、数据处理算法)上给予领域团队充分自由。
- 投资开发者体验:平台的成功与否直接取决于领域开发者的采纳度。将开发者体验作为平台设计的核心指标,持续简化交互流程,提供详尽文档和积极支持。
- 建立联邦治理模型:成立由各领域代表和平台专家组成的联邦治理委员会,共同制定和演进数据治理标准,确保其既满足全局要求,又贴合业务实际。
###
在数据网格架构中,强大而灵活的数据处理与存储支持服务是连接分布式数据领域与实现整体数据价值的枢纽。它通过将基础设施复杂性平台化、标准化,真正赋能领域团队成为其数据的主人,从而构建出一个既能快速响应业务变化,又能确保数据可信、安全与合规的现代化数据生态系统。对于志在实现数据规模化运营的企业而言,投资建设这样的支持服务平台,是迈向数据驱动未来的关键一步。
如若转载,请注明出处:http://www.shuduyouxi.com/product/30.html
更新时间:2026-03-01 03:15:07