微服务架构下数据统一分析、报表与数据处理存储支持服务的设计与实践
在微服务架构成为主流的今天,业务系统被解耦为一系列小型、自治的服务,每个服务拥有独立的数据库和技术栈。这种设计带来了灵活性、可扩展性和开发效率的提升,但也为数据统一分析、报表生成以及数据处理与存储带来了显著的挑战。数据分散在不同服务的独立数据库中,形成了“数据孤岛”,传统的集中式数据仓库或报表系统难以直接适用。本文将探讨在微服务之后,如何构建一套高效、可靠的数据统一分析、报表及数据处理存储支持服务体系。
核心挑战
- 数据分散与异构性:每个微服务使用最适合其业务逻辑的数据库(如关系型、文档型、图数据库等),数据模型、存储格式和访问协议各不相同。
- 数据一致性(最终一致性):微服务间通过事件驱动进行异步通信,数据在全局视角下是最终一致的,这给需要强一致性快照的实时报表带来了困难。
- 查询复杂性:跨多个服务的复杂关联查询难以直接在源数据库上执行,性能低下且可能影响服务本身的可用性。
- 数据所有权与治理:数据由各自的服务团队管理,统一分析需要协调数据定义、质量标准和访问权限。
解决方案:构建统一数据分析平台
应对上述挑战,业界普遍采用构建一个独立于业务微服务系统的统一数据分析平台。该平台的核心目标是:在不干扰微服务独立性与自治性的前提下,集中、清洗、转换并存储数据,为分析、报表和下游数据应用提供单一、一致的视图。 其典型架构包含以下关键组件与服务:
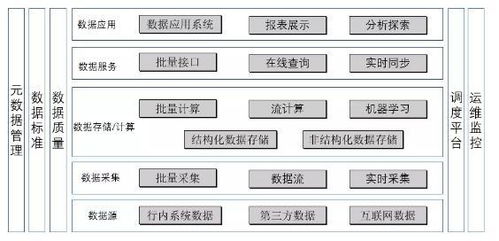
1. 数据集成与同步层
这是打破“数据孤岛”的第一步。主要模式有:
- 变更数据捕获(CDC):这是当前最主流且侵入性最低的方式。通过读取数据库的日志(如MySQL的binlog,PostgreSQL的WAL),实时捕获微服务数据库的增量数据变更(增、删、改),并将其作为事件流发布到消息中间件(如Kafka)。代表工具有Debezium。
- 事件溯源(Event Sourcing)与领域事件:如果微服务本身采用事件驱动架构并发布清晰的领域事件,可以直接将这些业务事件作为数据源。这包含了更丰富的业务语义。
- ETL/ELT定时批处理:对于实时性要求不高的场景,可以通过定时任务从微服务数据库或API中抽取数据。
2. 消息流与事件总线
一个高吞吐、可持久化的消息队列(如Apache Kafka)是平台的“中枢神经系统”。它承接来自CDC或微服务的事件流,提供了缓冲、解耦和可靠传递的能力。数据以流的形式在平台内流动。
3. 数据处理与转换层
此层负责将原始的、异构的数据流转化为适用于分析的统一模型。
- 流处理:使用流处理框架(如Apache Flink, Apache Spark Streaming, ksqlDB)对数据流进行实时清洗、过滤、丰富(如关联查找维表)和轻量聚合。适用于实时监控和实时仪表盘。
- 批处理:使用大数据处理框架(如Apache Spark, Hive)对积累的数据进行复杂的、重度的转换、关联和聚合,生成面向主题的宽表,供后续分析使用。
4. 统一数据存储层(分析数据存储)
经过处理的数据需要存储到适合分析的数据库中,与业务微服务的OLTP数据库分离。常见选择有:
- 云数据仓库:如Snowflake, BigQuery, Redshift。它们专为大规模分析查询设计,支持SQL,弹性伸缩,是存储统一分析数据的理想选择。
- 数据湖:如基于HDFS或对象存储(如AWS S3)构建的数据湖,存储原始和加工后的所有数据,格式开放(Parquet, ORC)。其上可搭载查询引擎(如Presto/Trino, Hive)进行交互式分析。
- OLAP数据库:如ClickHouse, Druid, StarRocks。它们为海量数据的亚秒级多维分析而优化,特别适合作为实时报表和即席查询的后端。
5. 数据服务与API层
为前端报表、BI工具(如Tableau, Superset, Metabase)和业务应用提供标准化的数据访问接口。
- SQL查询服务:通过统一的SQL网关(如Trino)访问底层多种数据存储。
- 分析API:将常见的分析查询封装成RESTful API或GraphQL API,供前端应用调用。
- 报表生成服务:一个专门的服务,负责按计划或触发条件执行预定义的复杂查询,生成报表文件(PDF, Excel)或填充报表模板,并通过邮件、消息等方式分发。
6. 元数据管理与数据治理
这是保障平台长期健康运行的关键支撑服务。
- 数据目录:记录所有数据资产的来源、含义、格式、血缘关系(从哪个微服务来,经过哪些处理)和变更历史。工具如Apache Atlas, DataHub。
- 数据质量监控:定义数据质量规则(如完整性、唯一性、有效性),并持续监控数据管道各环节的质量。
- 访问控制与审计:基于角色(RBAC)或属性(ABAC)控制对分析数据和报表的访问权限,并记录所有数据访问行为。
实践建议与演进路径
- 从报表需求出发,反向设计:首先明确核心报表和分析需求,确定所需的数据范围、粒度和时效性,再倒推需要集成哪些微服务的数据。
- 分阶段实施:
- 阶段一(解耦报表):针对最紧急的报表,通过CDC将关键数据同步到一个独立的只读副本或分析库,让报表查询与业务数据库分离。
- 阶段二(构建管道):引入消息队列和流/批处理框架,建立规范的数据管道,开始构建统一的数据模型(维度建模)。
- 阶段三(平台化):建设统一的数据存储、数据服务层和元数据管理系统,形成完整的自助分析平台。
- 拥抱“数据网格”理念:对于超大规模组织,可以考虑“数据网格”范式。它将数据视为产品,由各个业务领域团队(对应微服务团队)负责提供其“数据产品”(如清洗好的领域数据API或数据集),而中央平台提供通用的基础设施(如管道工具、存储、治理框架)。这更符合微服务的去中心化哲学。
- 确保可观测性:对整个数据流水线进行全面的监控(延迟、吞吐量、错误率)和告警,确保数据分析的及时性和可靠性。
结论
微服务架构下的数据统一分析并非要将数据重新中心化到单一数据库,而是通过构建一个基于事件流、现代数据栈的异步数据平台来实现。该平台尊重微服务的边界,通过CDC等技术非侵入式地集成数据,经过流批一体的处理,存储于专门的分析型数据库中,最终通过统一的数据服务支撑报表、BI和分析应用。这一过程不仅解决了眼前的报表难题,更是为企业构建数据驱动能力奠定了坚实、可扩展的基础。关键在于平衡好微服务的自治性与企业级数据一致性的需求,并配以持续的数据治理。
如若转载,请注明出处:http://www.shuduyouxi.com/product/39.html
更新时间:2026-03-01 00:48:46